
Introduction
In today's web development landscape, web applications require a bundler to transpile, combine, and optimize the source code of a project so that end users receive distributable code that is optimally packaged for downloading and executing within their browser.
Bundlers themselves have been around for a while, gaining more features as web applications have become more complex.
Many bundlers have appeared over the years, each learning from their predecessors and brining with them distinct features and advancements - such as;
- Dead code elimination (commonly known as tree shaking)
- Federated modules
- Hot module reloading
- Faster build times
- Faster run times
- etc
Many web tools are written in JavaScript or TypeScript, like the TypeScript compiler itself. Recently, a popular trend has been to create build tooling using a language better suited to handling the demanding workloads of those tools.
A common choice is Rust - rspack, turbopack. Another common choice is Go - esbuild.
Both languages offer fantastic features to enable building high performance and aggressively multi-threaded bundlers.
An interesting case study for writing a multi-threaded bundler in JavaScript is the Parcel bundler.
Parcel brought to the bundling world many novel features; like incremental bundling, a cache system, a plugin system that is both ergonomic and sensible, and an opinionated zero-configuration (or minimal-configuration) build environment.
This allowed for drastically simplified development environments that had a reduced burden of dependency maintenance.
Parcel's plugin system allowed for extensibility where required, however by default Parcel ships everything you need to build a modern web application.
In addition - Parcel leverages Node.js worker threads, scheduling jobs across threads, to improve bundling performance.
This series will embark on a journey to create a simple bundler, written in Rust, that is heavily inspired by the philosophy that Parcel embodies.
Disclaimer:
Throughout the series, I will analyze and compare Parcel with our creation - this isn't intended as a criticism of Parcel or aimed at insinuating that my spin off is better than Parcel.
There is simply no way that I, alone, could create something as comprehensive as Parcel. Parcel is a project with many brilliant and dedicated contributors and ultimately a lot of what I will be creating here will be taken directly from Parcel - borrowing learnings from their work that I never would have come to myself.
Objective
We are going to write our own bundler in Rust, one that targets building applications which exist at "hyper" scale.
I define hyper scale as an application that has tens of thousands of source files - presumably operating with millions of users (aspirational I know).
I picked this target because this is a context where conventional bundler tooling tends to struggle and the biggest gains from threading are to be had.
I would like to preserve the plugin model offered by Parcel as best as possible as I find it to be extremely ergonomic, supporting both dynamically loaded plugins written in Rust and plugins written in JavaScript.
This first article will center around the creation of the first phase in the bundling process - transformation.
Bundler Phases At A High Level
Parcel's bundling pipeline follows roughly the following flow:
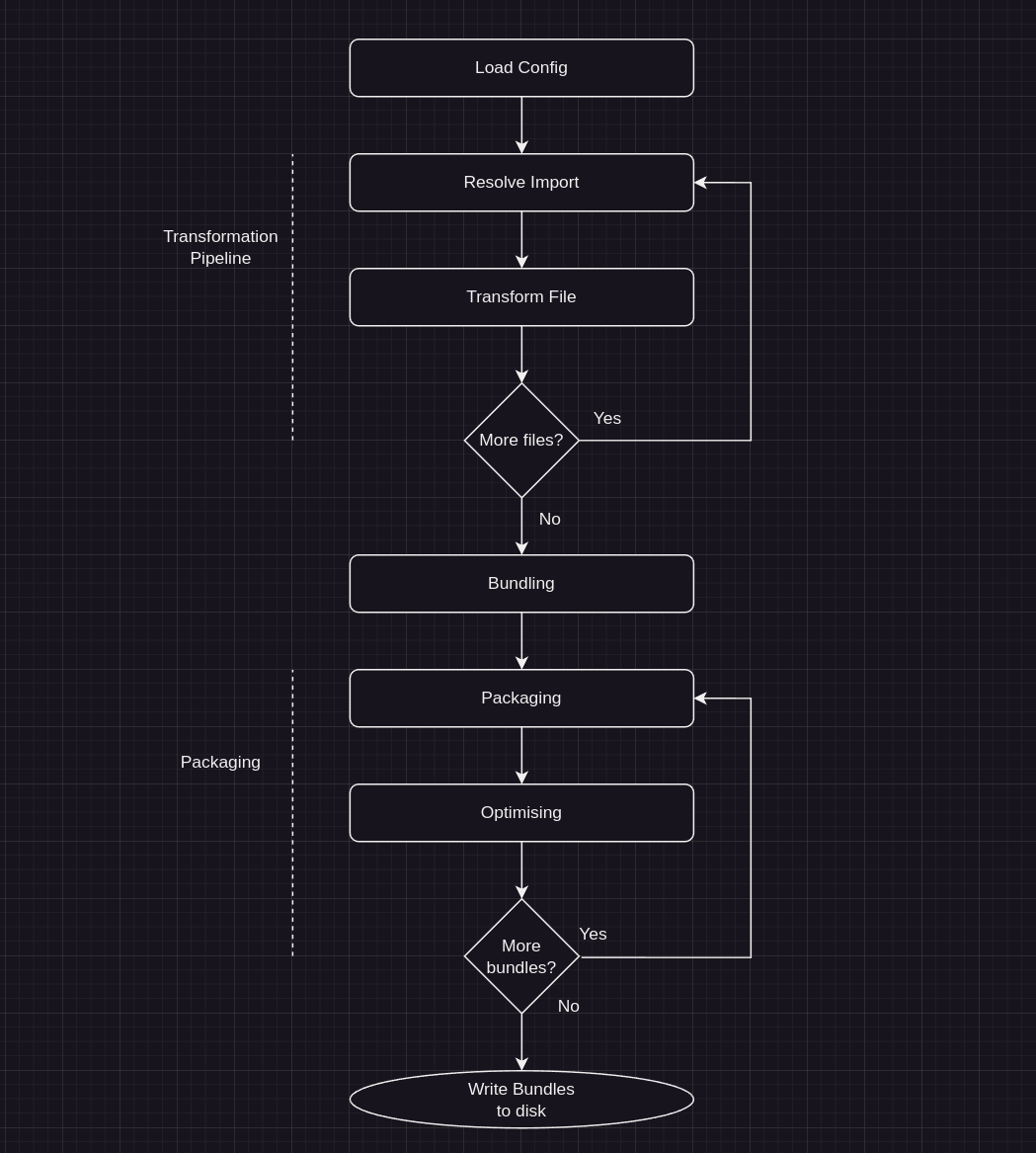
You can also view a more descriptive flow diagram on Parcel's website
The Transformation Pipeline
The transformation pipeline is a simple recursive loop (in behavior, not implementation) that traverses over the source files of a project; where imports are extracted and used to trigger the next loop.
The loop exits when there are no more imports to resolve and all the files have been processed.
The transformation pipeline is broken down into 2 major steps
- Resolving imports
- Transforming Files
To start off, an "entry" file is passed into the pipeline, the
import declarations are extracted resulting in the pipeline
discovering new files to transform - continuing the loop.
The new found files have their import declarations
extracted, again continuing the loop, stopping once all the
imports in a project have been extracted.
During transformation, the file is read, potentially converted from TypeScript to JavaScript then stored in memory within a "store".
Parcel actually writes these transform results to disk but for the sake of simplicity, we will keep them in memory unless it becomes a problem.
Resolution
The first step in the transformation loop is dependency resolution. To understand resolution we must first understand JavaScript imports.
Simply, JavaScript imports adhere to the following syntax:
The string used as the target of an import is known as the "specifier".
The specifier could be a relative path, absolute path, or an alias with rules described by the runtime or the bundler.
A bundler written in JavaScript can inherit some of these resolution properties, however a bundler written in Rust must reimplement them.
Thankfully, Parcel has a Rust crate that implements the Node.js resolution algorithm - which we will use as is.
To resolve an import, the bundler needs two pieces of information:
-
A
frompath - describing the absolute path of the file doing the importing - A
specifier- describing the thing being imported
The resulting output of an import resolution is an absolute path to the target file of the import statement.
Example
Transforming the file contents and extracting new specifiers
After the specifier has been resolved to an absolute path of the dependency, the absolute path is passed to the transformer.
The transformer will read the file contents from the disk then, using a JavaScript parser like SWC, will convert the source code into an AST.
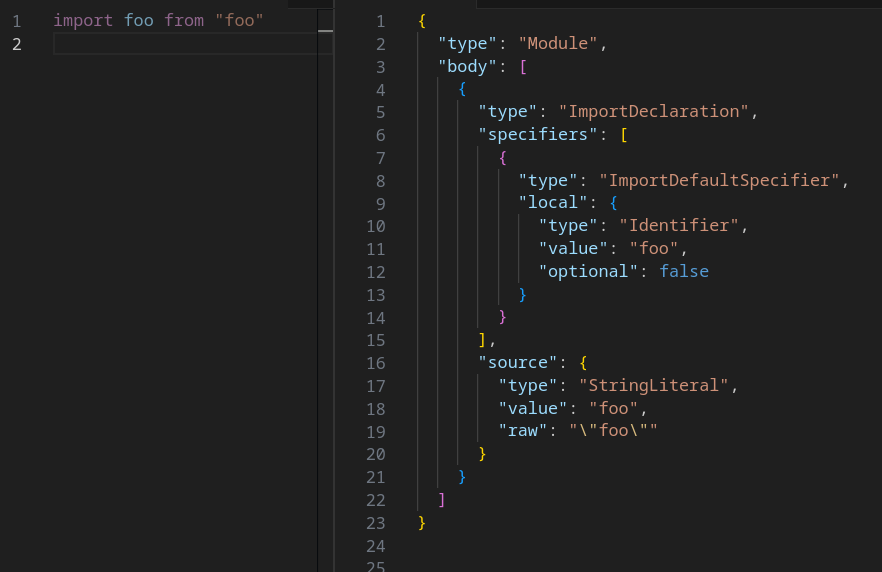
We can then walk the AST, identify the imports, extract the specifiers and give them to the next iteration of the loop.
Once again, Parcel has a Rust crate for its transformation step that we will use in our bundler. We will actually reimplement this later on in the series, but it will be helpful in getting us off the ground.
Example
A file with the contents:
Will see the transformer return following information to be used in the next iteration of the transformation pipeline loop:
The Benchmark
So let's get started.
The first thing we need is something to bundle. For this I have taken the familiar three-js benchmark used by esbuild, Parcel and other bundlers.
Three JS is a suitable benchmark because it has a large dependency graph, non trivial transformations, is written using valid module syntax and has no external dependencies.
To scale the benchmark up; we take the three-js source code and copy it 250 times. This results in a project that contain approximately 90,000 source files.

We then need to generate an entry point that imports each copy and re-exports it to avoid the bundler optimizing away unused imports.
Test Hardware
I will be using my personal desktop computer that has the following hardware:
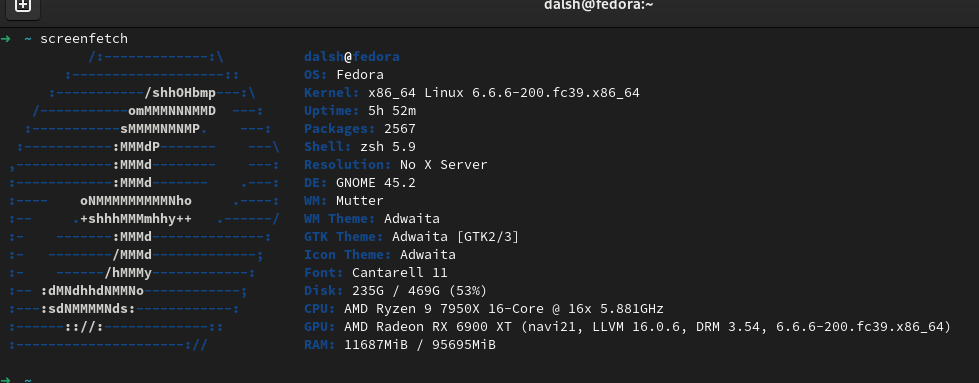
| Item | Details |
|---|---|
| CPU | AMD Ryzen 7950x - 16 Cores @ 5.8ghz (SMT off) |
| RAM | 98 GB |
| SSD | PCI-E NVMe SSD (silly fast I/O) |
| OS | Fedora Linux 39 |
| Node | v20.10.0 |
Baseline
To obtain a baseline for performance, I compiled the benchmark project using Parcel and recorded the resource usage with procmon.
The number of worker threads Parcel spawns is controlled with the
PARCEL_WORKERS environment variable, by default it has a
maximum value of 4.
Node.js has a quirk where the process has an explicit heap memory
ceiling which applies to the main process as well as to worker threads.
By default node grants something like 1gb per thread. For the build to
pass I had to increase Node.js's worker memory ceiling with the
node --max-old-space-size=xxxx command line argument to 6gb
per thread.
Unfortunately, the project size was too great and Parcel was unable to compile the entire project, however I was able to complete the transformation pipeline and profile that successfully - the build fails during the later optimization stage.
Parcel was able to compile a project with 50 copies of three-js, I have yet to determine the point at which it becomes too large
Results
Note: Keep in mind this is not a full build, this is just the transformation phase of the build
Running the build we see the following results:
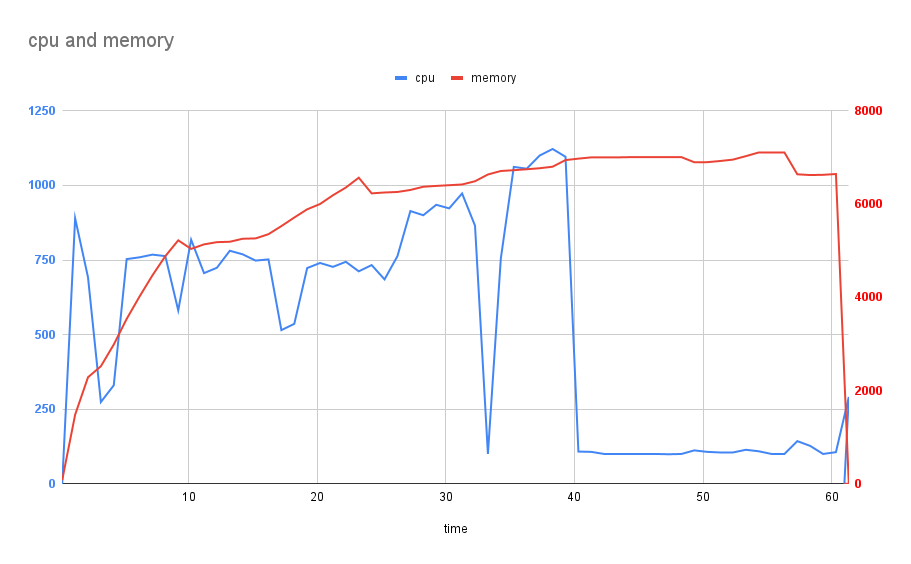
The transformation took 60 seconds where the CPU usage peaked at about 11 cores and averaged 5 cores. The process consumed 7gb of RAM.
Let's inspect the relationship between the number of threads against the transformation time.
To do this I am using the following bash:
When the PARCEL_WORKER variable is set to 0,
Parcel will run the compilation on the main thread. So that means
main thread + n workers = total threads.
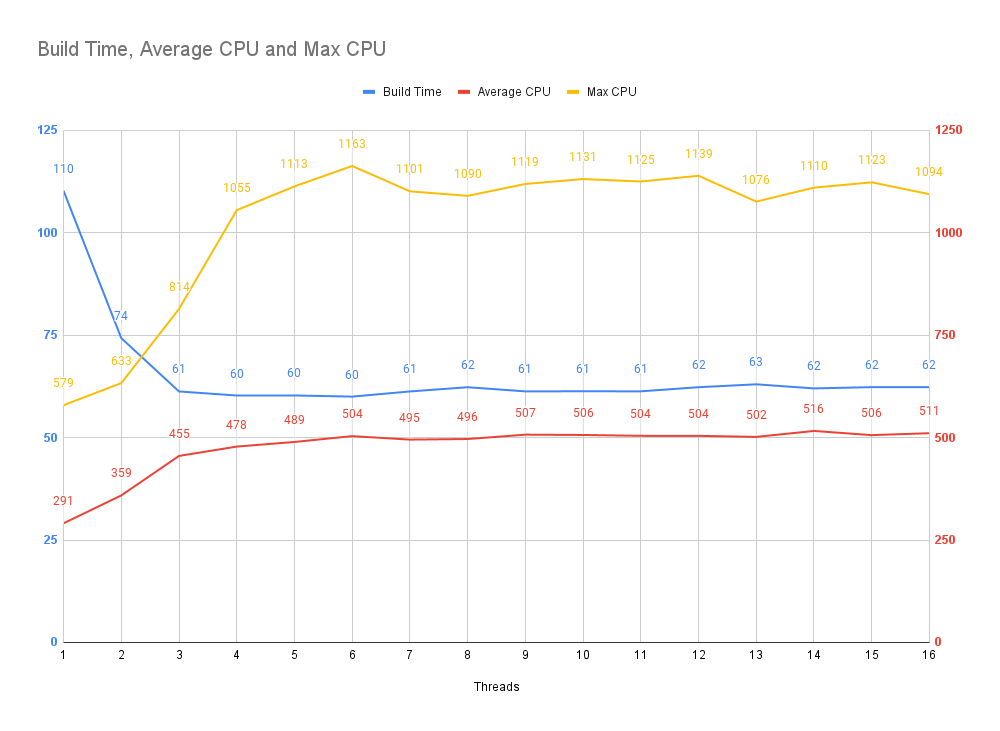
What we can observe is that we stop seeing improvements beyond 4 threads however there is a continued escalation of maximum CPU usage, while average CPU usage remains the same.
Why does Parcel behave like this?
Parcel.js is largely written in JavaScript and runs in a Node.js environment. While hot paths within Parcel are written as native Rust modules - the orchestration logic and data structures are held in JavaScript.
In most languages, state can be shared between threads where race conditions can be mitigated through the use of mutexes or other such forms of synchronization.
Node.js, by contrast, completely isolates each thread - making shared mutable access impossible (or impractical).
Instead, multi-threaded Node.js applications rely on the
postMessage API to send messages between threads - where
actions can be triggered independently of each other thereby eliminating
the possibility of race conditions.
Data sent via postMessage is cloned using a lightweight
deep clone implementation present in the
structuredClone()
function.
Node.js does not allow complex types like classes, functions or object containing functions to be sent across threads, however basic data types are permitted:
Example
An example of how communication across threads occurs.
There is one type that Node.js allows sending across workers which does
facilitate shared mutable state - the SharedArrayBuffer.
A SharedArrayBuffer is essentially a fixed sized array with
0|1 values within it.
Mutations to the SharedArrayBuffer are available instantly
through threads as it's a shared mutable reference - however you
need to cast normal data types (like string, etc) into the
SharedArrayBuffer and read them out of the buffer.
This necessitates complex wrappers and, should you need more size than
the SharedArrayBuffer contains, you must create a new
SharedArrayBuffer instance and manually stitch together
pages.
This makes using a SharedArrayBuffer highly impractical for
most use cases.
Parcel stores the state of the bundle graph within pages of
SharedArrayBuffer instances, however that is not used
within the transformation pipeline.
During transformation, we are simply concerned with resolving and
converting files - during this phase Parcel simply clones and sends many
internal data structures between threads using postMessage.
The main thread acts as an orchestrator for this communication however in a project that is large enough, the main thread will be unable to cope with managing the messaging for more than a few CPUs at a time - forcing cores to sit idle waiting for work while the orchestrator is overwhelmed with the side quest of copying/serializing stuff.
That said, what the Parcel team have accomplished within the context of Node.js is truly remarkable. Parcel is a case study that demonstrates just how far you can push Node.js in terms of performance and, in the arena of bundlers written in JavaScript, Parcel outperforms every single one!
Side note: Parcel currently has an experimental implementation of a shared structured memory utility currently in RC phase known as ParcelDB. The Parcel team has the ambition to migrate Parcel to Rust in the future, however this must be an incremental process. ParcelDB aims to facilitate this migration while simultaneously improving the performance of the existing bundler. It's super cool.
Bundlers and other similar build tools must efficiently scale vertically on client machines to make maximal use of the available hardware and deliver an outstanding experience and it appears that, at the time of writing, Node.js presents a poor substrate for high performance multi-threaded applications.
So let's try figure out how to do it in Rust!
Let's Build A Bundler (Transformer)
TypeScript
Reviewing the circuit for the transformation pipeline, it's possible to create a simple, single threaded implementation in TypeScript that serves as a familiar environment to describe the flow.
Now in Rust
This is a good starting point and is not that different when ported to Rust (link to source):
That's pretty sweet... how does the single threaded Rust transformer perform?
Results
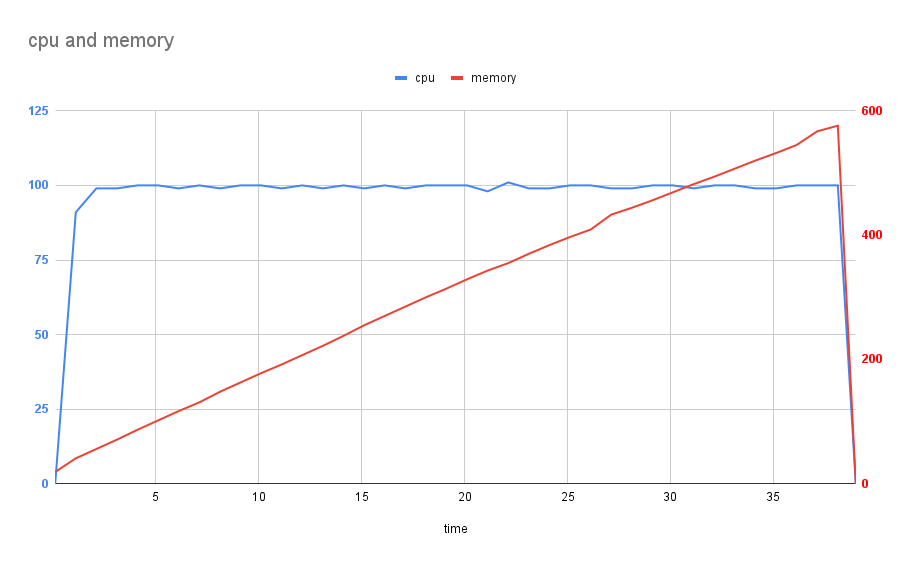
Looking at the chart, on a single thread, our home baked transformer circuit was able to transform the 90k source file three-js benchmark in 40 seconds and consumed 600mb of ram while doing it!
As expected, the CPU was locked at 1 core being used at 100% and the memory usage grew linearly as the contents of the files were loaded into memory.
To be fair, Parcel stores a lot more information about assets and the environment the bundler is running in - however this is a pretty impressive result.
Multithreading
Let's try to make this circuit multi-threaded.
The simplest approach is to spawn a number of OS threads and protect the shared data structures behind mutexes.
In Rust this is done by wrapping them in an
Arc<Mutex<T>> like this:
An Arc is a "smart pointer", which you can think
about as a clone-able reference to the value contained within. In effect
an Arc<String> can be thought of as a
*String.
So here we go (link to source):
Results
Running this circuit against the 250x three-js project using 16 threads:
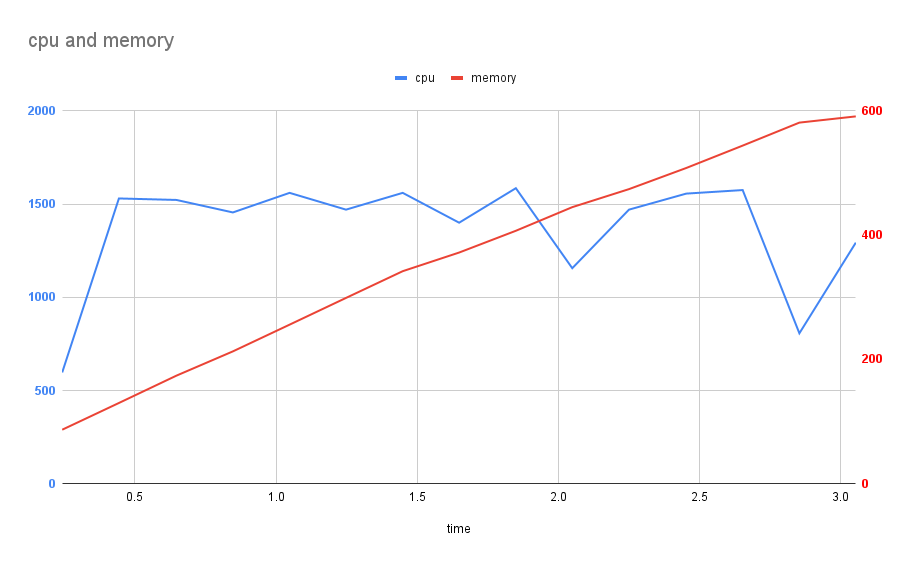
🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯 3 seconds!?
Doing some napkin math, given the single threaded run took 40 seconds; 40 seconds divided by 16 cores is 2.5 seconds - so a transformation time of 3 seconds does make sense and indicates there is the potential to improve this further at some point.
In reality you never see gains that match dividing the time a single threaded task took by the number of threads, but we did get pretty close!
Another interesting thing to note is that the library I am using to track CPU usage started to lose it with the higher CPU utilization.
Let's have a look at the build time vs thread count looks like:
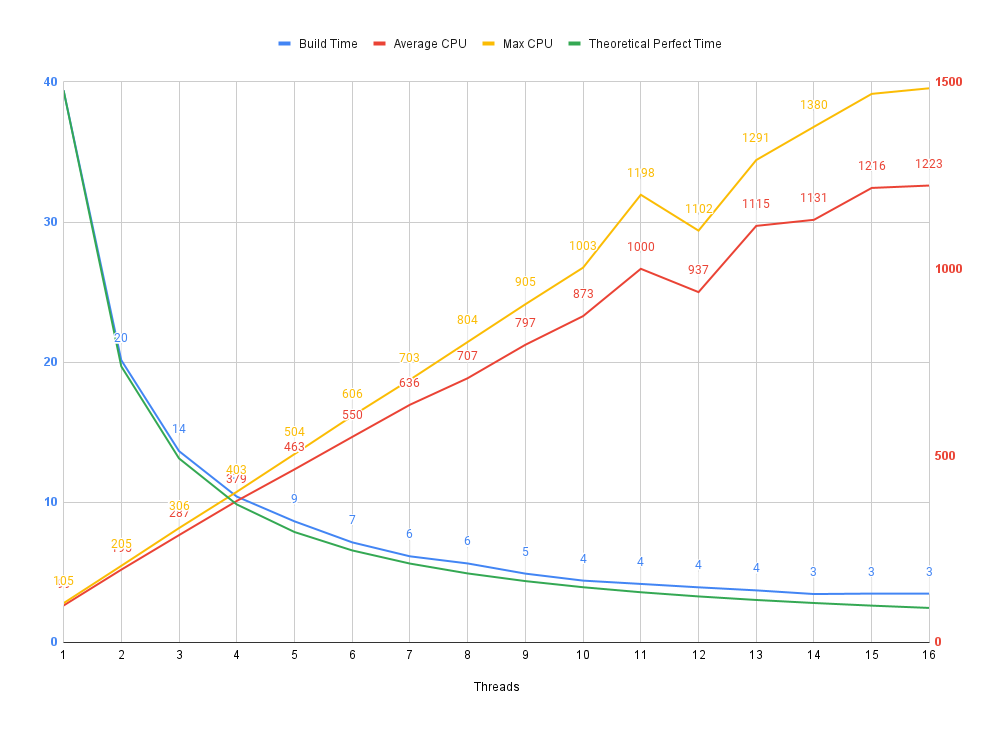
The blue line tracks the actual build time.
The green line tracks the "theoretical perfect" build time,
calculated as build time of 1 thread / number of threads
Red and yellow track average and maximum CPU usage.
We can see that we are able to track very closely to the theoretical perfect time and it's likely not worth optimizing further to achieve a better time.
A benefit of this approach is that a time of 6 seconds is still very acceptable, limiting the thread count to 7 leaves us with 9 threads to continue working on other tasks while the build runs - like checking emails or watching YouTube videos.
Comparison to Parcel
While this transformer circuit attempts to mimic Parcel's transformation circuit - it does not completely encapsulate the work that Parcel is doing.
For example, Parcel is loading plugins dynamically, it's checking assets to determine which plugins to use on them, detecting configuration and supplying it to plugins.
It also support many more language features, automatically detecting if
the file uses TypeScript or JSX. It supports Node's
require() syntax as well as JavaScript's
import syntax.
It's also generating a much more complex graph of the asset relationships to use for advanced optimizations like dead code elimination.
While we do see a 20x improvement in the time it takes for this circuit to run - this isn't indicative of the real world expectations of how a bundler like Parcel would perform if migrated to Rust.
That said, it does make me excited to see how the Parcel project performs once migrated to Rust - there certainly seems a lot to be gained in the way of performance.
Next Article
In the next article we will dive into bundling. We will walk through analyzing the asset graph to determine when to combine source files and generate a "bundle graph".
FIN 🌴